

Statistical Text Mining (Sample Publications)
The goal of text mining is to extract useful information (e.g., "topic", "sentiment", etc.) from text corpora. While this has been a big research area in Natural Language Processing and Machine Learning, there are comparably fewer works from the statistical literature. Statistical approaches to text mining focus on Modeling (suitable statistical models to capture real complications yet still remain tractable), Methods (scalable algorithms that leverage classical statistical ideas such as Principal Component Analysis, latent space estimation, and variable screening), and Mathematical theory (minimax optimality, phase transitions). I have worked on several text mining problems, including topic modeling, supervised sentiment analysis, multi-gram text models, and information retrieval.
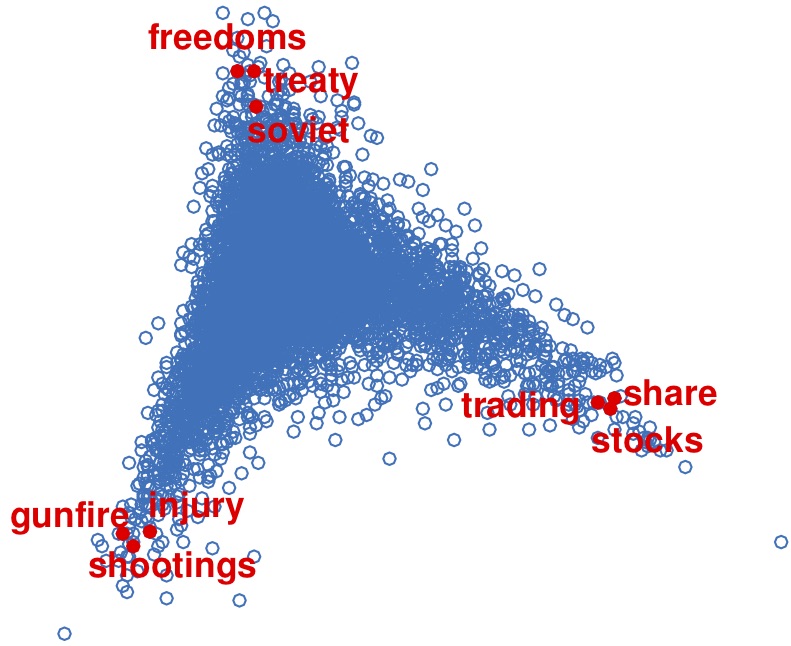
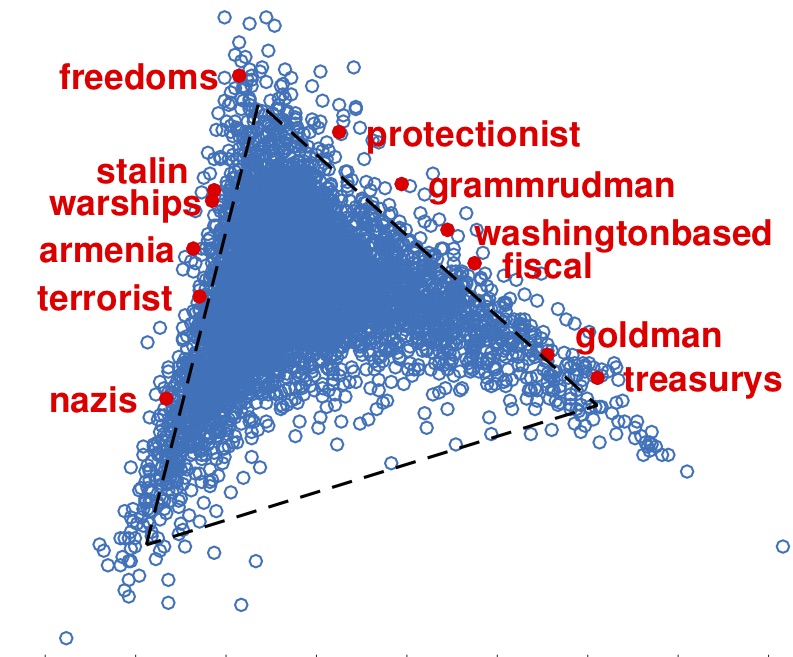
The above figures show a particular word embedding by the method Topic-SCORE, where the words in each of the three vertices are the anchor words of three topics, Politics, Crime and Finance, and the words on edges are the words relevant to two out of three topics.
Social Network Analysis (Sample Publications)
The popularity of large online social networks has motivated many recent research works on statistical analysis of network data. One problem of great interest is to uncover the latent community structure. However, real networks are complicated, often with extreme sparsity, severe degree heterogeneity, and mixed memberships. My research focus is to develop effective methods that can handle these challenges, especially severe degree heterogeneity. I have worked on problems including global testing, community detection, mixed membership estimation, and hypergraph analysis.
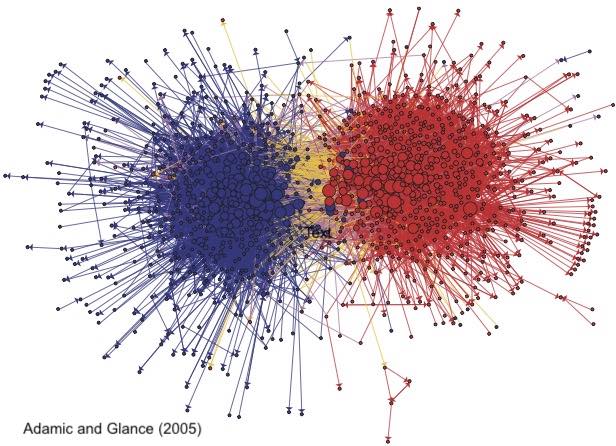
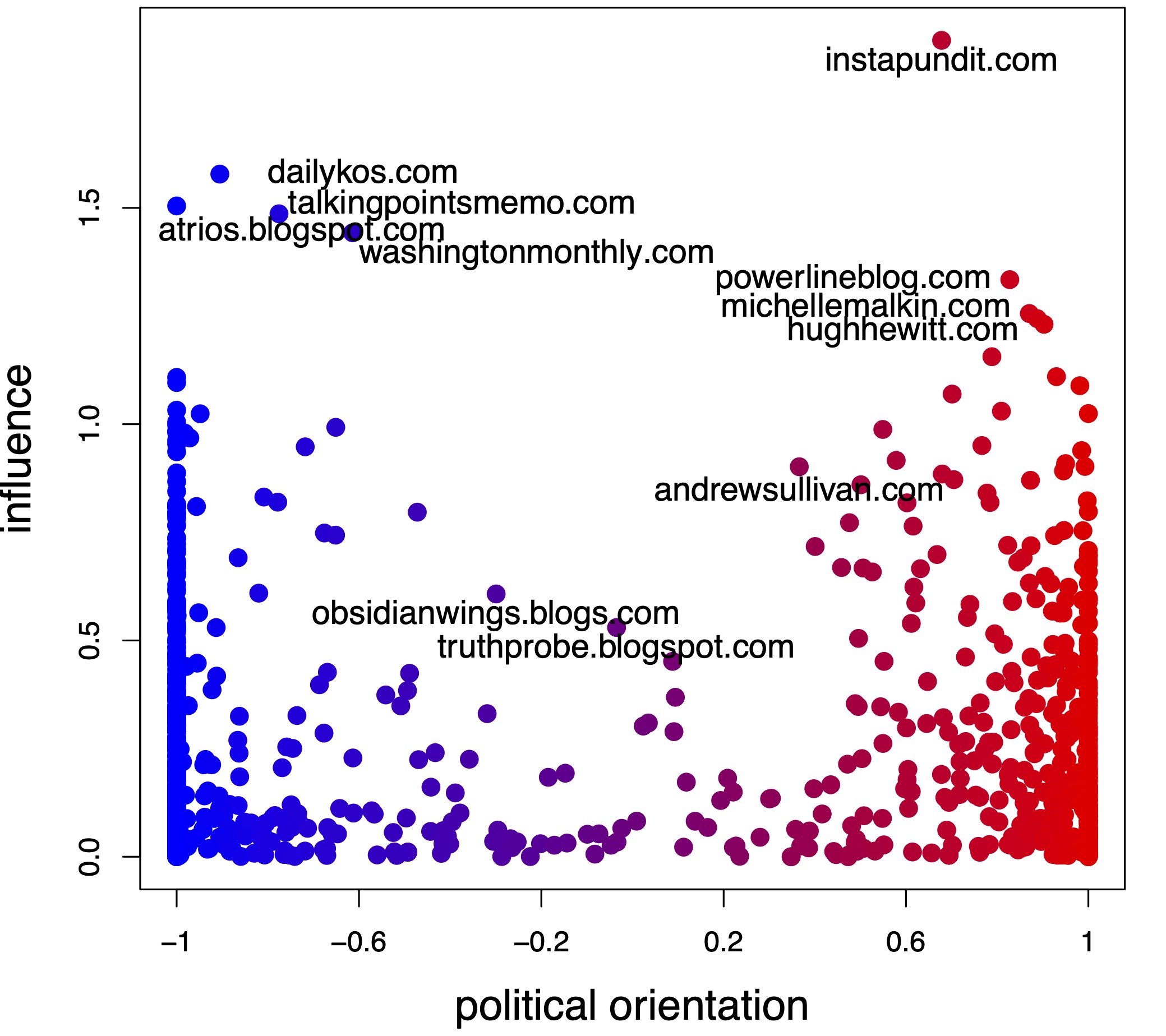
The above figures provide an example of mixed membership estimation on a political network by the method Mixed-SCORE, where the estimated mixed membership shows the political orientation of each blogger.
Sparse Inference, especially for Rare/Weak signals (Sample Publications)
.jpg)
Sparsity is a natural phenomenon found in many large-scale data sets, and exploiting the sparsity (called "sparse inference") has become a common strategy for analyzing Big Data. My research on sparse inference focuses on Rare/Weak signals: in many applications such as genetics, genomics, finance, cosmology and astronomy, the signals or true effects we are looking for are very few, far apart, and very weak individually; they are hard to find and it is easy to be fooled. The Rare/Weak viewpoint partially explains why many published scientific research are not reproducible.
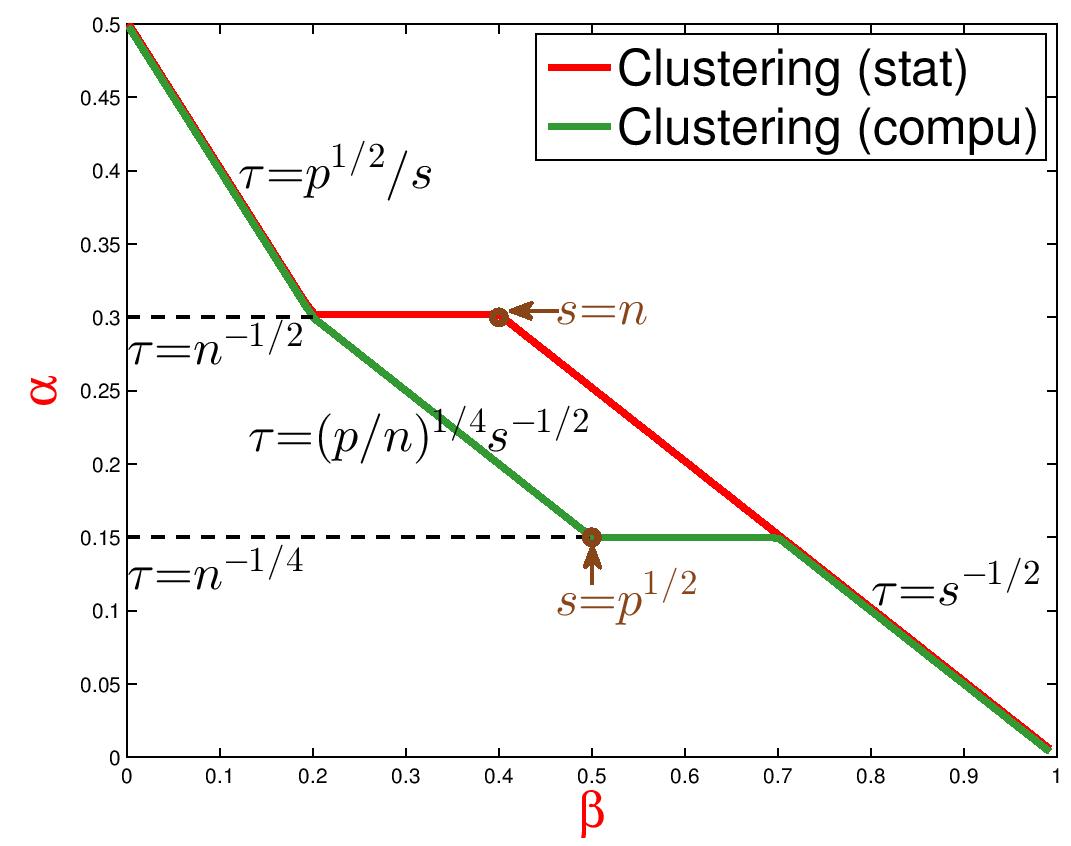
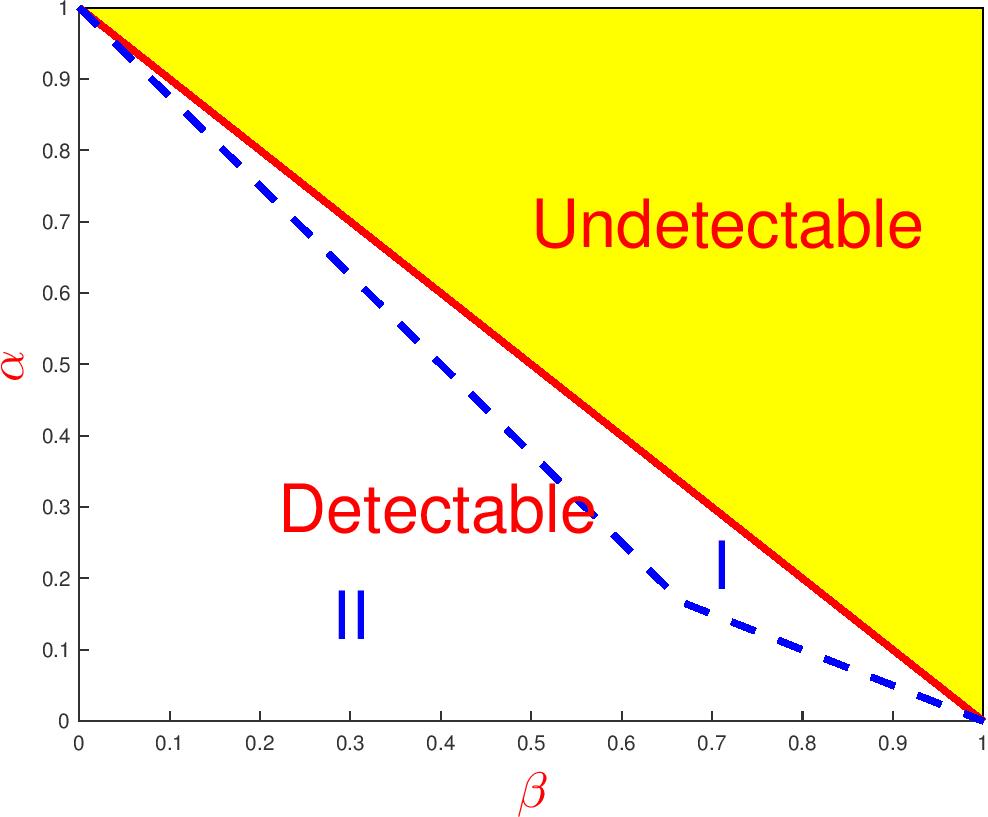
The Phase Diagram is a platform for accessing the fundamental limits of statistical tasks and studying optimality of methods in the Rare/Weak signal settings. The two-dimensional phase space calibrates the "signal rareness" and "signal weakness", respectively, and in different regions of the phase space, statistical inference is different. The figures above show the (theoretical) phase diagrams in my work for variable selection (left), clustering (middle) and detection of spiked covariance matrix (right).
Dataset of Statisticians' Coauthorship and Citations (Website)
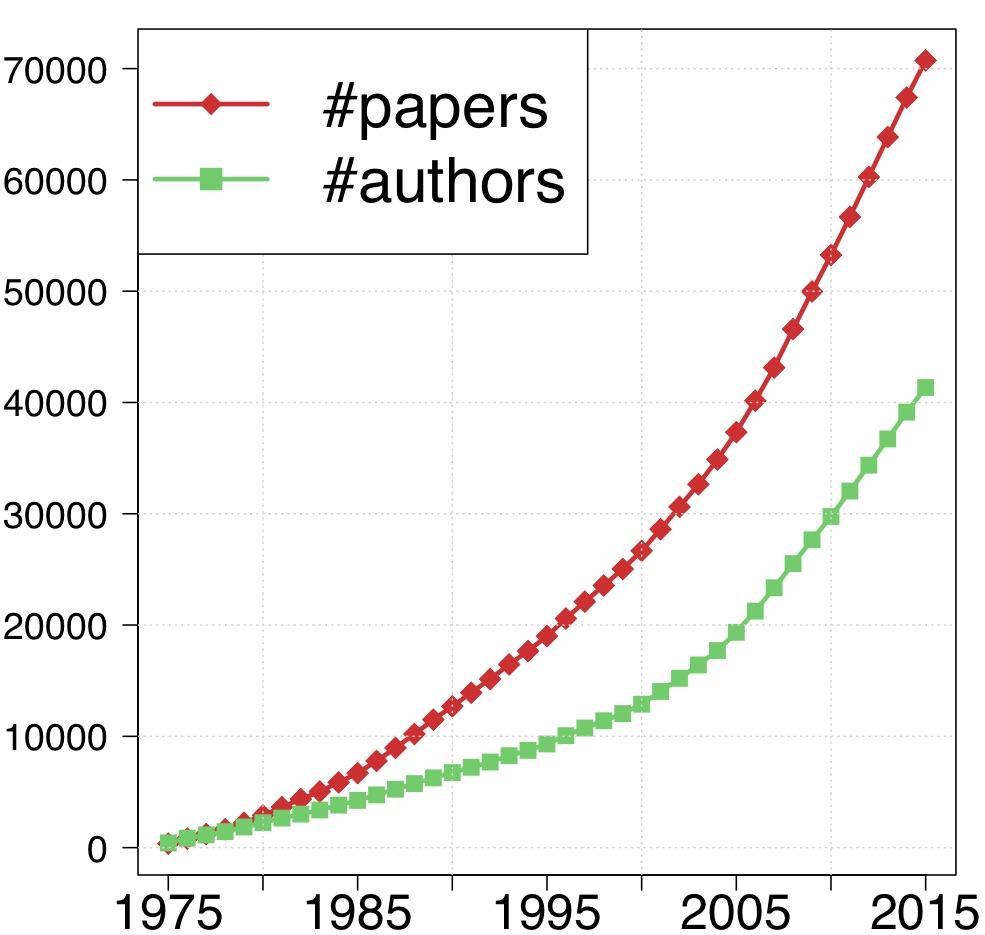
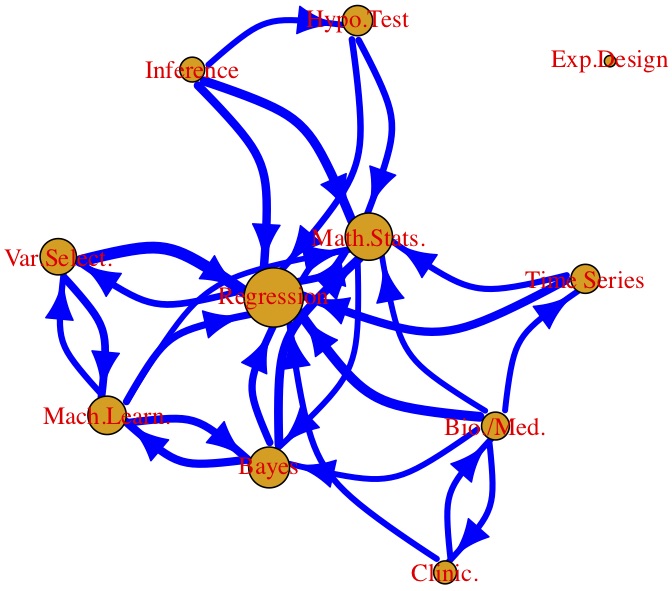
My collaborators and I have collected and cleaned a large data set for the networks of statisticians. The data set consists of the title, authors, abstracts, MSC numbers, references, and citation counts for 83K papers published in 36 representative journals in statistics, probability, machine learning, and related fields, spanning 41 years. The data set provides a fertile ground for research in social networks, text mining, bibliometrics, and knowledge discovery, and motivates an array of interesting research problems. We have studied an array of problems including overall productivity for statisticians, journal ranking, citation patterns, citation prediction, topic learning and topic weight estimation, network analysis and dynamic networks.